
SEMに携わっている方なら1度は利用したことのあるGoogle トレンド。入力した検索語句(検索クエリ)の検索トレンドを時系列で追うことができるツールです。
前述したように、Google トレンドでは検索トレンドが視覚的に表示され、これまでの流行り廃りがグラフとなって一目で分かるため、とても利用度の高いツールであるのですが、「このデータは何を持って作られているのか?」という視点を持っていないと誤った判断をしてしまいかねません。
備忘録的にGoogle トレンドの仕組みを簡単に紹介いたします。
Contents
トレンドデータ≠検索ボリュームの絶対数
Google トレンドにおけるデータは「実数から算出された相対値」から成り立ったデータになり、さらにその中では大きく3つの要素を反映した相対値をトレンドとして表示させています。
検索ボリューム(実検索回数)の絶対値ととらわれがちなのですが、実際は検索ボリュームをシステムで「正規化」して処理された相対値のデータである事を覚えておきましょう。
データの正規化とは
Wikipediaの「正規化」によると、
正規化(せいきか、英: normalization)とは、データ等々を一定のルール(規則)に基づいて変形し、利用しやすくすること。別の言い方をするならば、正規形でないものを正規形(比較・演算などの操作のために望ましい性質を持った一定の形)に変形することをいう。
ちょっと抽象的で分かりにくいですね・・・。
正規化についてはその考え方や手法によって色々ととらえ方がありますが、統計の専門の方の目を恐れつつも例を1つ上げてみますと「正規化によって物事を0~100パーセントの間の尺度で表す」。つまり数値をパーセンテージのように全体のうちどのくらいの割合を占めているかで表せれば、2つのものを1つの尺度で比較することができるようになると言うものです。
例えばうどん県と言われるほどうどんをよく食べる香川県と、東京都ではどちらがうどんの「消費量」が多いでしょうか?と考えたときに、絶対値である「消費量」としては恐らく香川県よりも人口が13倍ある東京都の方が「量」としては多いかもしれません。それで言うと多くの食べ物でも人口が多い東京都が「消費量」トップになりかねません。ともすれば、各都道府県●●の消費量を比べるとしたときに人口の重みが大きすぎて比較にならないことは明らかです。
ですが、「人口1人あたりの消費量」としてデータを加工することで人口によるデータの偏りをなくしてみるとどうでしょうか。週4日~5日、強者になると週7日はうどんを食べていると言われている香川の方々のほうが圧倒的に多いでしょう。このように値を比較しやすくする為の変換作業を正規化と呼びます。
Google トレンドで表示されるデータはこのような正規化がされており、それは相対値なのです。
1. データは「検索ボリュームの総数」で正規化
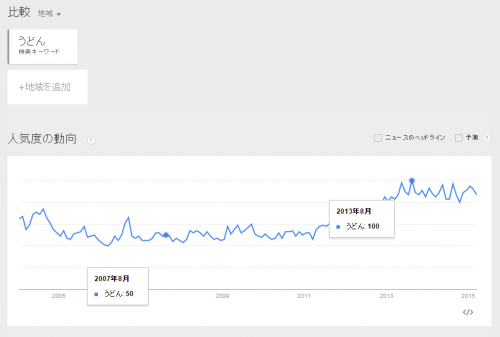
1つは総検索ボリュームにおける正規化です。例えば次のグラフを見て下さい(かなり大雑把な例えです)。
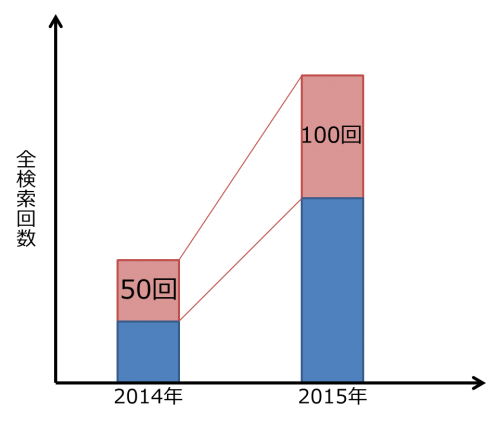
2014年において検索語句Aは50回、2015年には100回に増えました。では、この検索語句Aは2014年と比べてトレンド(流行)という意味で更に流行ったのでしょうか?それとも廃れたのでしょうか?ここで先ほどの「うどん」の話を振り返ってみましょう。総量が違う物の中で、単純に絶対値を比較しても比較にならない、意味をなさないと言うことでしたよね。なので、このデータを全体の検索回数で正規化してみます。
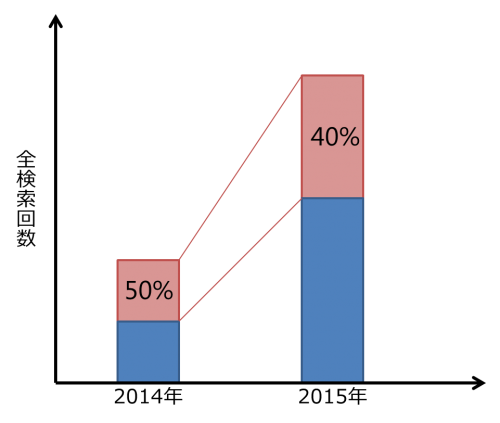
正規化してみるとこうなります。
正規化して比較をしてみた結果「実検索回数は倍近く増えているが、全検索回数に占める割合は50%から40%に下がっている」と言うことがこの例では言えますね。検索の割合が下がっていると言うことは、トレンドとしては下がってきていると言うことになります。ただし、Google トレンド表示される数値は、さらにその他の複数要素も含めて正規化がされているので、例えば2014年の50%(全期間で見たときにピーク値だったとして)を100とすると、2014年は80のように、正規化された数値を基準にまた正規化されるような形をとるため、Google トレンドの数値から全検索回数の実数などは逆算できないようになっています(おそらく)。
また、ここで注意しなければならないのは、上記例のように検索回数とトレンドは必ずしも連動しないと言うことです。実検索回数が増えるとトレンドが上がる、実検索数が減るとトレンドが下がるというのは必ずしも成立しないと言うことは覚えておきましょう。
2. データは「地域」で正規化
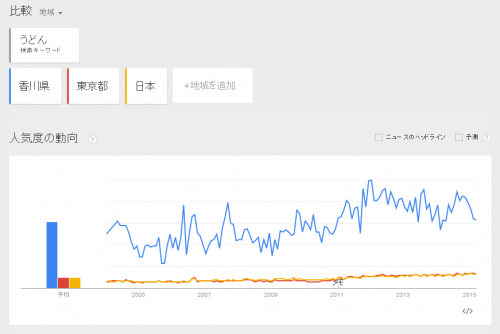
Google トレンドのデータはどの地域を対象とするかでデータが正規化されます。ざっくり言いますと「対象地域における当該キーワードの検索回数」÷「対象地域における総検索回数」になります。「うどん」のトレンドでいうと香川県は、東京都単体もしくは東京・香川を含む全国のトレンドと比較しても高いことが分かります。これによって、地域によって検索語句の価値が違うと言うことが知れますし、他の地域と比較しやすくなるわけです。
※2015年8月5日追記:正規化のざっくり計算式において言葉足らずでしたので追記しました。「検索回数」→「対象地域における当該キーワードの検索回数」
3. データは「時間軸」で正規化
データは時間軸でも正規化がされます。
Google トレンドで表示している期間の中でのピークだった年月を100としたときに、他の年月ではそれと比べてどの程度だったか比較できるように正規化がされます。これによって過去の実検索回数に左右されずにその検索語句のトレンドがどのように変化していたかを知ることができます。
まとめ
Google トレンドはその仕組みを知らないと、いわゆる数のマジックにはまってしまい、判断を誤ってしまうこともあります。レポートなどでも同じ事が言えますが、その数値はどういった意味を持つのか?と言った疑問を持ちながらデータと向き合うと言うことは非常に重要なことであると言えます。






[…] 参考:Google トレンドとデータ正規化のお話 | SEM Insight […]